От чего зависит пропускная способность шины?
Пропускная способность памяти видеокарты и ее зависимость от «битности»
Мы продолжаем серию статей по разбору основных характеристик видеокарты, и на очереди у нас: пропускная способность памяти, а также прямо влияющий на неё показатель – ширина шины памяти видеокарты.

Ширина шины или сколько бит «нужно»
Ширина шины памяти – важнейший параметр, который косвенно влияет на общую производительность видеокарты. Сама по себе шина – это канал, соединяющий память и графический процессор видеокарты. А от ширины шины зависит количество данных, которое может быть передано графическому процессору и обратно в память за единицу времени. Соответственно, чем больше ширина шины видеопамяти, тем лучше. Рост производительности особенно заметен в требовательных играх, которые подкреплены утяжелением в виде максимального сглаживания и анизотропной фильтрации .
Теперь, давайте рассмотрим несколько популярных классов «битности» шин памяти:
64 бита — довольно популярный класс видеокарт бюджетного сегмента рынка. Видеокарты с такой шиной позиционируются для «облагораживания» бюджетных систем (но и то, там зачастую царят интегрированные решения), а также домашних ПК с нетребовательными задачами к графической производительности системы. Особенно смешно смотрятся такие видеокарты с большим объёмом видеопамяти на борту.
128 бит – средний класс. Изредка, можно увидеть в бюджетных видеокартах, и очень часто в видеокартах middle-сегмента. Зачастую, такие видеокарты пригодны для полноценных домашних систем, с довольно широкими игровыми задачами, но часть игр всё равно будет «неподъёмной» для данного класса.
256 и 384 бит – топовый класс. Зачастую, «идёт» в сочетании с отменными частотными показателями, как памяти, так и ядра, безусловно, – это максимальная игровая производительность для всего и сразу.
Но, хотелось бы подчеркнуть, что данная классификация является очень и очень условной, потому что нельзя оценивать видеокарту по одной лишь ширине шины памяти. К тому же, сама по себе «битность», влияет на производительность лишь с жёсткой зависимостью от частоты видеопамяти. Эти два параметра рассчитывают пропускную способность памяти видеокарты (ПСП).
Поэтому, чтобы уверенно говорить относительно оптимальной величины шины, нужно рассматривать всё в комплексе, то есть, саму ПСП. Чем мы сейчас и займёмся.
Пропускная способность памяти
Как уже говорилось выше, данный показатель зависит от двух параметров: частоты памяти и ширины шины.
С помощью нехитрой формулы можно найти пропускную способность памяти, к примеру, какой-нибудь из видюшек на чипе Radeon HD 7970.
Возьмем модель с эффективной частотой памяти 6000 МГц и шириной шины 384 бита (48 байт если перевести). ПСП= эффективная частота памяти х ширину шины памяти = 6000 х 48 = 288 Гбайт/с. Величину ПСП также можно посмотреть с помощью специальных программ, к примеру, GPU-z.
Также, предлагаю ознакомиться с довольно интересной шкалой актуальности ПСП современных видеокарт. Конечно, тут тоже всё очень неоднозначно — ведь «не одной лишь ПСП живём», но всё же, вполне логичную зависимость можно отследить:

Какая же ширина шины оптимальна? Ответ на данный вопрос для каждого случая будет отличаться. Во-первых, нужно отталкиваться от задач, которые будут выполняться с помощью будущей системки. Во-вторых, необходимо помнить про баланс в параметрах видеокарты. Поэтому для определенной конфигурации, должна быть подобрана видеокарта с определенной шириной шины и другими показателями. И зависят они от задач и только от них.
ПСП на пару с шириной шины, не сделают «погоды», если видюшка укомплектована слабым графическим процессором , с плохими частотными показателями. GPU просто не сможет «переваривать» те объёмы данных, которые буду поступать по более быстрой шине.
Поэтому, как итог, можно еще раз смело напомнить: баланс и еще раз баланс!
От чего зависит пропускная способность шины?
Технологии шагнули очень далеко вперед
Частота шины процессора
- Главная   /  Статьи   /  
- Частота шины процессора
Частота шины процессора
Front Side Bus
Front Side Bus (FSB, системная шина) — шина, обеспечивающая соединение между x86/x86-64-совместимым центральным процессором и внутренними устройствами.
Как правило, современный персональный компьютер на базе x86- и x64-совместимого микропроцессора устроен следующим образом:
- Микропроцессор через FSB подключается к системному контроллеру, который обычно называют «северным мостом», (англ. Northbridge).
- Системный контроллер имеет в своём составе контроллер ОЗУ (в некоторых современных персональных компьютерах контроллер ОЗУ встроен в микропроцессор), а также контроллеры шин, к которым подключаются периферийные устройства.
Получил распространение подход, при котором к северному мосту подключаются наиболее производительные периферийные устройства, например, видеокарты с шиной PCI Express x16, а менее производительные устройства (микросхема BIOS’а, устройства с шиной PCI) подключаются к «южному мосту» (англ. Southbridge), который соединяется с северным мостом специальной шиной. Набор из «южного» и «северного» мостов называют набором системной логики, но чаще применяется калька с английского языка «чипсет» (англ. chipset).
Таким образом, FSB работает в качестве магистрального канала между процессором и чипсетом.
Некоторые компьютеры имеют внешнюю кэш-память, подключённую через «заднюю» шину (англ. back side bus), которая быстрее, чем FSB, но работает только со специфичными устройствами.
Каждая из вторичных шин работает на своей частоте (которая может быть как выше, так и ниже частоты FSB). Иногда частота вторичной шины является производной от частоты FSB, иногда задаётся независимо.
Влияние на производительность компьютера
Частота процессора
Частоты, на которых работают центральный процессор и FSB, имеют общую опорную частоту, и в конечном счёте определяются, исходя из их коэффициентов умножения (частота устройства = опорная частота * коэффициент умножения).
Память
Следует выделить два случая:
Контроллер памяти в системном контроллере
До определённого момента в развитии компьютеров частота работы памяти совпадала с частотой FSB. Это, в частности, касалось чипсетов на сокете LGA 775, начиная с 945GC и вплоть до X48.
Основная статья: Список чипсетов Intel
То же касалось и чипсетов NVIDIA для платформы LGA 775 (NVIDIA GeForce 9400, NVIDIA nForce4 SLI/SLI Ultra и др.)
Основная статья: Сравнение чипсетов Nvidia Основная статья: nForce 700 Основная статья: nForce 600
Спецификации стандартов системной шины чипсетов на сокете LGA 775 и оперативной памяти DDR3 SDRAM
| Стандартное название | Частота памяти, МГц | Время цикла, нс | Частота шины, МГц | Эффективная (удвоенная) скорость, млн. передач/с | Название модуля | Пиковая скорость передачи данных при 64-битной шине данных в одноканальном режиме, МБ/с |
|---|---|---|---|---|---|---|
| DDR3‑800 | 100 | 10,00 | 400 | 800 | PC3‑6400 | 6400 |
| DDR3‑1066 | 133 | 7,50 | 533 | 1066 | PC3‑8500 | 8533 |
| DDR3‑1333 | 166 | 6,00 | 667 | 1333 | PC3‑10600 | 10667 |
| DDR3‑1600 | 200 | 5,00 | 800 | 1600 | PC3‑12800 | 12800 |
| DDR3‑1866 (O.C.) | 233 (O.C.) | 4,29 (O.C.) | 933 (O.C.) | 1866 (O.C.) | PC3‑14900 (O.C.) | 14933 (O.C.) |
O.C. — в режиме overclocking (разгона)
Поскольку процессор работает с памятью через FSB, то производительность FSB является одним из важнейших параметров такой системы.
На современных персональных компьютерах, начиная с сокета LGA 1366 частоты компьютерной шины, которая называется QuickPath Interconnect, и шины памяти могут различаться.
Периферийные шины
Существуют системы, преимущественно старые, где FSB и периферийные шины ISA, PCI, AGP имеют общую опорную частоту, и попытка изменения частоты FSB не посредством её коэффициента умножения, а посредством изменения опорной частоты приведёт к изменению частот периферийных шин, и даже внешних интерфейсов, таких как Parallel ATA. На других системах, преимущественно новых, частоты периферийных шин не зависят от частоты FSB.
В системах с высокой интеграцией контроллеры памяти и периферийных шин могут быть встроены в процессор, и сама FSB в таких процессорах отсутствует принципиально. К таким системам можно отнести, например, платформу Intel LGA1156.
Центральный процессор
Центральный процессор – устройство, непосредственно осуществляющее процесс обработки данных. Основная задача процессора – это интерпретация команд и рассылка соответствующих управляющих сигналов к другим устройствам. Процессоры в ПЭВМ выполнены в виде одной микросхемы и потому называются такжемикропроцессорами.
Основные характеристики процессора:
длина слова (разрядность);
Тактовая частотапроцессора число элементарных операций — тактов, выполняемых в течение одной секунды. В современных ПЭВМ под тактовой частотой понимается внутренняя частота. Обмен данными с внешним миром осуществляется на частоте системной шины, которая всегда меньше внутренней частоты процессора. Тактовая частота грубо характеризует скорость работы процессора.
Длина слова(разрядность процессора) – это максимальное количество разрядов двоичного кода, которые могут передаваться или обрабатываться одновременно за один такт. Все современные микропроцессоры 32 или 64 разрядные.
Применительно к ПЭВМ понятие «разрядность» включает:
разрядность внутренних регистров (внутренняя длина слова);
разрядность шины данных (внешняя длина слова);
разрядность шины адреса.
Разрядность внутренних регистров определяет формат команд процессора и размер данных, с которыми можно оперировать в командах.
Разрядность шины данных определяет скорость передачи информации между процессором и другими устройствами.
Разрядность шины адреса определяет размер адресного пространства, т.е. максимальное число байтов, к которым можно осуществить доступ. Например, если разрядность шины адреса равна 16, то возможный размер памяти в ЭВМ равен 216=65536 или 65 Кб.
Архитектура процессора – это очень ёмкое понятие, в составе которого можно рассматривать следующие элементы:
способ организации вычислительного процесса;
Система команд – полный список кодов операций, которые способен выполнять процессор. По составу команд различают: CISC-архитектуру и RISC-архитектуру .
Большинство ЭВМ использует CISC-архитектуру. Основная идеяRISC– так упростить команды процессора, чтобы они могли быть выполнены за один такт. Это позволяет спроектировать очень эффективный конвейер команд.
Набор команд процессора определяет его функциональное назначение, в соответствии с которым различают универсальные и специализированные процессоры.
Универсальный процессор способен реализовать любой алгоритм и используется в качестве центрального процессора. Специализированный процессор служит для решения задач определённого класса. Среди таких сопроцессоров можно выделить математические и графические процессоры.
С системой команд связано такое важное свойство, как совместимость. Два процессора называются совместимыми, если их системы команд одинаковы.
Программу ускорения клавиатуры можно записать в машинном языке:
B8 05 03 BB-00 00 CD 16-CD 20
или в переводе на автокод
B80503 mov ax,00305
BB0000 mov bx,00000
Данная программа использует систему команд процессора Intel8086 и без изменений может быть перенесена на процессорыIntel80286, 80386, 80486,PentiumI,PentiumII,PentiumIII. Поэтому все эти процессоры называются совместимыми снизу вверх. Сверху вниз эти процессоры несовместимы, так как, например,PentiumIIIимеет команды, которые не поддерживаются процессоромPentiumI.
Для повышения эффективности вычислительного процесса в современных микропроцессорах применяется конвейернаяисуперскалярнаяобработки данных.
Процессор может иметь устройства, которые позволяют использовать его в многопроцессорной конфигурации. Работа в мультипроцессорномрежиме обеспечивается как архитектурой процессора, так и возможностями операционной системы. Например,Windows95 не имеет такой поддержки, аWindowsNTServerподдерживает четыре процессора.
Архитектура микропроцессора Pentiumимеет следующие особенности:
суперскалярная конвейерная архитектура;
конвейерное вычисление с плавающей точкой;
повышенная разрядность внешней шины данных.
Разрядность регистров – 32 бит, шины адреса — 32 бит, шины данных — 64 бит. Производительность микропроцессора PentiumIс тактовой частотой 66 МГц оценивается в 112MIPS.
Оценка производительности различных микропроцессоров приведена в табл. 2.3.
Шина PCIe: только ли физические ограничения влияют на скорость передачи?
Начну издалека. Прошлой зимой довелось мне делать USB-устройство с ядром, размещаемым в ПЛИС. Само собой, очень мне хотелось проверить реальную пропускную способность этой шины. Ведь в контроллере — там слишком много всего наверчено. Всегда можно сказать, что вот тут внесена задержка, или вон там. В случае же с ПЛИС — я вижу блок, прокачивающий данные, вот он сказал мне, что в нём данные есть. А вот я выставил, что всё обработано, и я готов принимать новую порцию (при этом, он уже принимает данные во второй буфер этой же конечной точки). Отлично, ставим готовность с первого же такта и смотрим, что получается, когда USB может «молотить» без остановки.
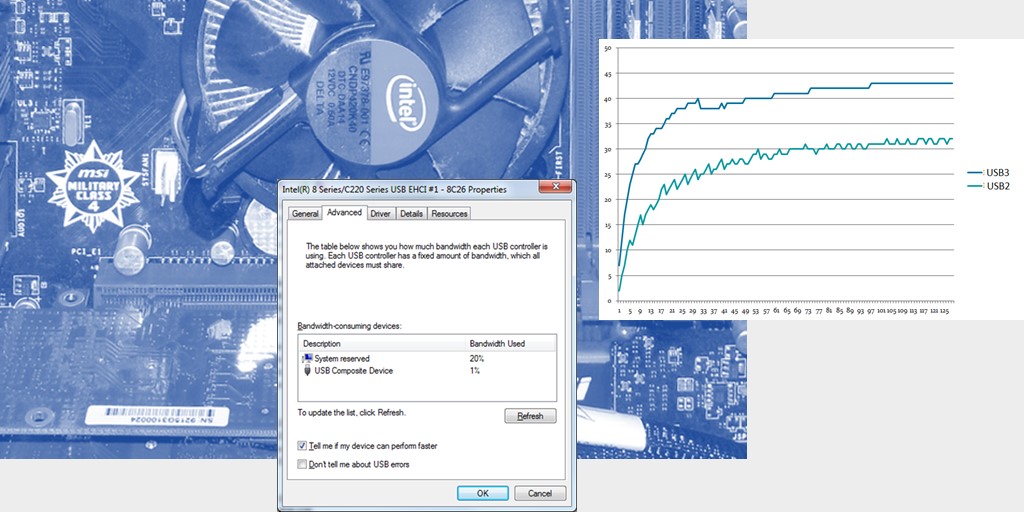
А получается удивительная вещь. Если USB 2.0 устройство воткнуто в «голубенький» разъём (это который USB 3.0), то скорость получается одна. Если в «чёрненький» — другая. Вот мой график зависимости скорости записи в USB от длины передаваемых данных. USB3 и USB2 — это тип разъёма, устройство всегда USB 2.0 HS.
Я пробовал в разных машинах. Результат — близок. Никто не мог объяснить мне этот феномен. Уже потом я нашёл наиболее вероятную причину. А причина очень проста. Вот свойства контроллера USB 2.0:

У контроллеров, управляющих «голубеньким» разъёмом такого нет. А разница — как раз примерно процентов 20.
Из этого мы делаем вывод, что не всегда ограничения пропускной способности определяются физическими свойствами шины. Иногда накладываются ещё какие-то вещи. Переходим с этими знаниями в наши дни.
Первичный эксперимент
Итак. Всё начиналось весьма буднично. Шла проверка одной программы. Проверялся процесс записи данных одновременно на несколько дисков. Аппаратура простая: имеется материнская плата с четырьмя PCIe-слотами. Во все слоты воткнуты совершенно одинаковые карточки с AHCI-контроллерами, каждый из которых поддерживает исключительно PCIe x1.

Каждая карта обслуживает 4 накопителя.
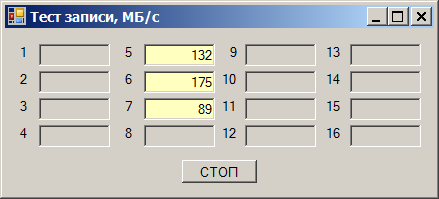
И вот выясняется следующий эффект. Берём один диск и начинаем записывать на него данные. Получаем скорость от 180 до 220 мегабайт в секунду (здесь и далее, мегабайт — это 1024*1024 байт):

Берём второй накопитель. Скорость записи на него — от 170 до 190 МБ/с:

Пишем сразу на оба — получаем просадку скорости:
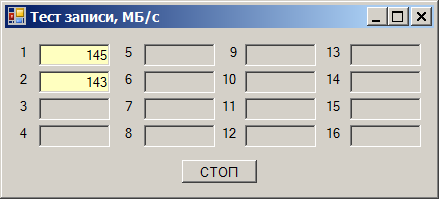
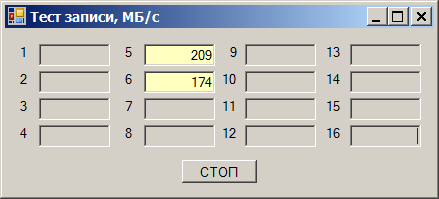
Суммарная скорость получается в районе 290 МБ/с. Но удивительность состоит в том, что отлаживали (так получилось) эту программу мы на тех же накопителях, но на других каналах. И там всё было хорошо. Быстро перетыкаем в те каналы (они будут идти через другую карту), получаем прекрасную работу:
Куплю слот в хорошем районе
Сразу скажу, что винить во всём какие-то чужие компоненты не стоит. Здесь всё написано нами, начиная от самой программы, заканчивая драйверами. Так что весь путь прохождения данных может быть проконтролирован. Неизвестность наступает только когда запрос ушёл в аппаратуру.
После первичного разбора выяснилось, что скорость не ограничивается в «длинных» слотах PCIe и ограничивается в «коротких». Длинные — это куда можно вставить карты x16 (правда, один из них работает в режиме не выше x4), а короткие — только для карт x1.

Всё бы ничего, но контроллеры в текущих картах в принципе не могут работать в режиме, отличном от PCIex1. То есть, все контроллеры должны быть в абсолютно идентичных условиях, независимо от длины слота! Ан нет. Кто живёт в «длинном» — работает быстро, кто в «коротком» — медленно. Хорошо. А быстро — насколько быстро? Добавляем третий накопитель, пишем на все три.
В «коротких» слотах ограничение всё ещё в районе 290 МБ/с:

В «длинных» — в районе 400 МБ/с:

Я перерыл весь Интернет. Во-первых, через некоторое время я уже смеялся со статей, где говорится о том, что пропускная способность PCIe gen 1 и gen 2 для x1 составляет 250 и 500 МБ/с. Это «сырые» мегабайты. За счёт оверхеда (я использую это нерусское слово, чтобы обозначить служебный обмен, идущий по тем же линиям, что и основные данные) для gen 2 получается именно 400 мегабайт в секунду полезного потока. Во-вторых, я упорно не мог найти ничего про магическую цифру 290 (забегая вперёд — до сих пор не нашёл).
Отлично. Пытаемся глянуть на топологию включения наших контроллеров. Вот она (013-015 — это суффиксы имён устройств, по которым я сопоставил их, чтобы как-то различать). Зелёные —быстрые, красные — медленные.
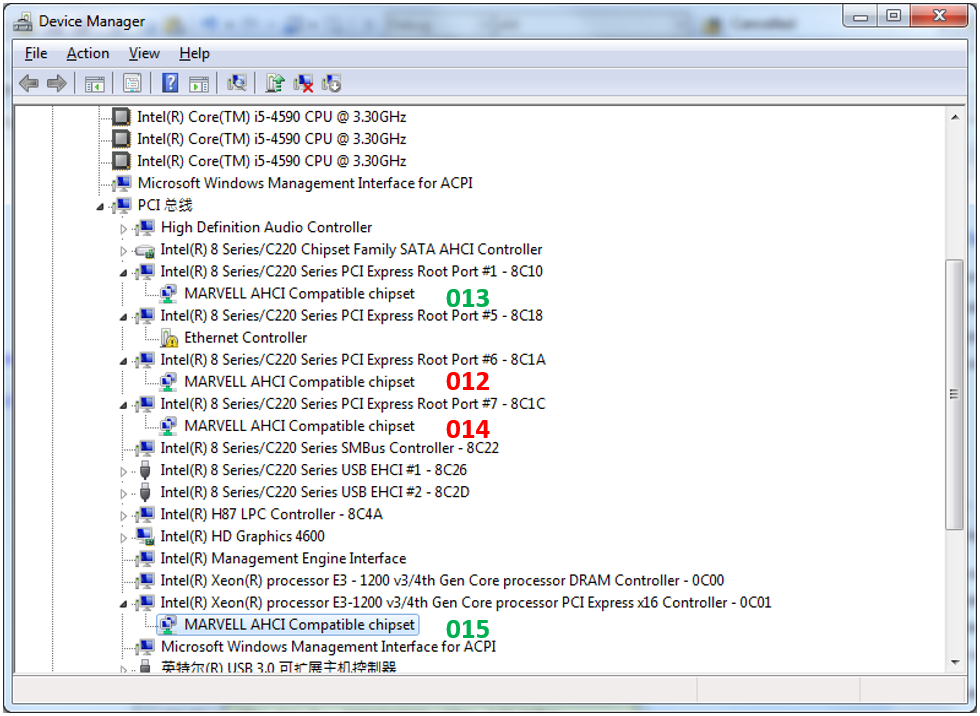
Контроллер «015» мы даже не рассматриваем. Он живёт в привилегированном слоте, предназначенном для видеокарты. Но 013-й подключён к тому же коммутатору, что и 012-й с 014-м. Чем он отличается?
Отдельные статьи говорят, что разные карты могут отличаться параметрами Max Payload. Я изучил конфигурационное пространство всех карт — этот параметр стоит у всех в одном и том же, минимально возможном значении. Мало того, в документации на чипсет этой материнки сказано, что иного значения и быть не может.

В общем, я перерыл всё в конфигурационном пространстве — всё настроено идентично. А скорость разная! Многократно перечитал документацию на чипсет — никаких настроек пропускной способности. Приоритеты — да, что-то про них написано, но тесты же ведутся при полном отсутствии нагрузки по другим каналам! То есть дело не в них.
На всякий случай, я даже отключил работу программы по прерываниям. Нагрузка на процессор возросла до безумных величин, ведь теперь он постоянно тупо читает бит готовности, но показания скорости не изменились. Так что обвинить в проблемах эту подсистему тоже нельзя.
А что там у других плат?
Попробовали поменять материнскую плату на точно такую же. Никаких изменений. Попробовали заменить процессор (были основания считать, что он барахлит). Тоже никаких изменений скорости (но старый процессор и правда барахлил). Поставили материнскую плату более нового поколения — всё просто летает на всех слотах. Причём предельная скорость уже не 400, а 418 мегабайт в секунду, хоть в «длинных», хоть в «коротких» слотах:

Но здесь — никаких чудес. Привычным движением руки (за эти дни уже привык) считываем конфигурационное пространство и видим, что параметр Max Payload установлен не на 128, а на 256 байт.
Больше размер пакета — меньше количество пакетов. Меньше оверхед на их пересылку — больше полезных данных успевает пробежать за то же время. Всё верно.
Так кто же виноват?
Точного ответа на вопрос из заголовка, со ссылкой на документы, я не дам. Но мысль моя пошла по следующему пути: допустим, что ограничение потока задано внутри чипсета. Его нельзя программировать, оно задано намертво, но оно есть. Например, оно равно 290 мегабайт в секунду на каждую дифф. пару. Больше — режется уже где-то внутри чипсета на его внутренних механизмах. Поэтому в «длинном» слоте (куда можно воткнуть карты вплоть до x4) внутри чипсета для нашей карты ничего не режется, а мы упираемся в физический предел шины x1. В «коротком» же разъёме мы упираемся в это ограничение.
На самом деле, проверить это не просто, а очень просто. Втыкаем в 013-й слот не AHCI, а SAS-контроллер, который обслуживает сразу 8 накопителей и может работать в режимах PCIe вплоть до x4. Подключаем ему 4 шустрых SSD накопителя. Смотрим скорость записи — аж душа радуется:

Теперь добавляем те 4 диска, которые фигурировали в первых тестах. Скорость работы SSD предсказуемо просела:

Вычисляем суммарную скорость, проходящую через SAS-контроллер, получаем 1175 мегабайт в секунду. Делим на 4 (столько линий идёт в «длинный» слот), получаем… Барабанная дробь… 293 мегабайта в секунду. Где-то я это число уже видел!
Итак, в рамках данного проекта было доказано, что дело не в нашей программе или драйвере, а в странных ограничениях чипсета, которые наверняка «зашиты» намертво. Была выведена методика подбора материнских плат, которые могут быть использованы в проекте. А в целом, выводы делаем следующие.
Как найти пропускную способность шины
Delphi site: daily Delphi-news, documentation, articles, review, interview, computer humor.
Второй характеристикой шины является пропускная способность, которая определяется количеством бит информации, передаваемых по шине за секунду.
Для определения пропускной способности шины необходимо умножить тактовую частоту шины на ее разрядность. Например, для 16-разрядной шины ISA пропускная способность определяется так:
(16 бит — 8,33 МГц) : 8 = (133,28 Мбит/с) : 8 = 16,66 Мбайт/с.
Отметим, что при расчете пропускной способности, например шины AGP, следует учитывать режим ее работы: благодаря увеличению в 2 раза тактовой частоты видеопроцессора и изменению протокола передачи данных удалось повысить пропускную способность шины в 2 (режим 2D) или в 4 (режим 4П) раза, что эквивалентно увеличению тактовой частоты шины в соответствующее количество раз (до 133 и 266 МГц соответственно).
В табл. 5.1 представлены характеристики некоторых шин ввода/вывода.
Таблица 5.1. Характеристики параллельных шин ввода/вывода
Мы продолжаем серию статей по разбору основных характеристик видеокарты, и на очереди у нас: пропускная способность памяти, а также прямо влияющий на неё показатель – ширина шины памяти видеокарты.

Ширина шины или сколько бит «нужно»
Ширина шины памяти – важнейший параметр, который косвенно влияет на общую производительность видеокарты. Сама по себе шина – это канал, соединяющий память и графический процессор видеокарты. А от ширины шины зависит количество данных, которое может быть передано графическому процессору и обратно в память за единицу времени. Соответственно, чем больше ширина шины видеопамяти, тем лучше. Рост производительности особенно заметен в требовательных играх, которые подкреплены утяжелением в виде максимального сглаживания и анизотропной фильтрации .
Теперь, давайте рассмотрим несколько популярных классов «битности» шин памяти:
64 бита — довольно популярный класс видеокарт бюджетного сегмента рынка. Видеокарты с такой шиной позиционируются для «облагораживания» бюджетных систем (но и то, там зачастую царят интегрированные решения), а также домашних ПК с нетребовательными задачами к графической производительности системы. Особенно смешно смотрятся такие видеокарты с большим объёмом видеопамяти на борту.
128 бит – средний класс. Изредка, можно увидеть в бюджетных видеокартах, и очень часто в видеокартах middle-сегмента. Зачастую, такие видеокарты пригодны для полноценных домашних систем, с довольно широкими игровыми задачами, но часть игр всё равно будет «неподъёмной» для данного класса.
256 и 384 бит – топовый класс. Зачастую, «идёт» в сочетании с отменными частотными показателями, как памяти, так и ядра, безусловно, – это максимальная игровая производительность для всего и сразу.
Но, хотелось бы подчеркнуть, что данная классификация является очень и очень условной, потому что нельзя оценивать видеокарту по одной лишь ширине шины памяти. К тому же, сама по себе «битность», влияет на производительность лишь с жёсткой зависимостью от частоты видеопамяти. Эти два параметра рассчитывают пропускную способность памяти видеокарты (ПСП).
Поэтому, чтобы уверенно говорить относительно оптимальной величины шины, нужно рассматривать всё в комплексе, то есть, саму ПСП. Чем мы сейчас и займёмся.
Пропускная способность памяти
Как уже говорилось выше, данный показатель зависит от двух параметров: частоты памяти и ширины шины.
С помощью нехитрой формулы можно найти пропускную способность памяти, к примеру, какой-нибудь из видюшек на чипе Radeon HD 7970.
Возьмем модель с эффективной частотой памяти 6000 МГц и шириной шины 384 бита (48 байт если перевести). ПСП= эффективная частота памяти х ширину шины памяти = 6000 х 48 = 288 Гбайт/с. Величину ПСП также можно посмотреть с помощью специальных программ, к примеру, GPU-z.
Также, предлагаю ознакомиться с довольно интересной шкалой актуальности ПСП современных видеокарт. Конечно, тут тоже всё очень неоднозначно — ведь «не одной лишь ПСП живём», но всё же, вполне логичную зависимость можно отследить:

Какая же ширина шины оптимальна? Ответ на данный вопрос для каждого случая будет отличаться. Во-первых, нужно отталкиваться от задач, которые будут выполняться с помощью будущей системки. Во-вторых, необходимо помнить про баланс в параметрах видеокарты. Поэтому для определенной конфигурации, должна быть подобрана видеокарта с определенной шириной шины и другими показателями. И зависят они от задач и только от них.
ПСП на пару с шириной шины, не сделают «погоды», если видюшка укомплектована слабым графическим процессором , с плохими частотными показателями. GPU просто не сможет «переваривать» те объёмы данных, которые буду поступать по более быстрой шине.
Поэтому, как итог, можно еще раз смело напомнить: баланс и еще раз баланс!
Пропускная способность — характеристика памяти, от которой зависит производительность и от которая выражает как произведение частоты системной шины на объем данных, передаваемых за такт. Однако, частота работы модуля памяти и теоретическая пропускная способность не единственные параметрами, которые отвечают за производительность системы. Не менее важную роль играет и тайминги памяти.
Пропускная способность (Пиковый показатель скорости передачи данных) – это комплексный показатель возможности RAM, в нем учитывается частота передачи данных, разрядность шины и количество каналов памяти. Частота указывает потенциал шины памяти за такт – при большей частоте, можно передать больше данных.
Пиковый показатель вычисляется по формуле:
Пропускная способность (B) = Частота передачи (f) x разрядность шины (c) x количество каналов памяти(k)
Если рассматривать на примере DDR400 (400 МГц) с двухканальным контроллером памяти пиковый показатель скорости передачи данных равен:
(400 МГц x 64 бит x 2)/ 8 бит = 6400 Мбайт/с
На 8 мы поделили, чтобы перевести Мбит/с в Мбайт/с (в 1 байте 8 бит).
Пропускная способность
Для быстрой работы компьютера пропускная способность шины оперативной памяти должна совпадать с пропускной способности шины процессора. К примеру, для процессора Intel core 2 duo E6850 с системной шиной 1333 MHz и пропускной способностью 10600 Mb/s, нужно купить две оперативные памяти с пропускной способностью 5300 Mb/s каждая (PC2-5300), в сумме они будут иметь пропускную способность системной шины (FSB) равную 10600 Mb/s.
При высоких скоростях обработки данных присутствует один минус — высокое выделения тепла. Для этого производители уменьшили напряжение питания памяти DDR3 до 1.5 В.
Двухканальный режим
Для увеличения скорости обмена данных и увеличения пропускной способности современные чипсеты поддерживают двухканальную архитектуру памяти.

Если установить два, абсолютно идентичных, модули памяти, тогда будет использован двухканальный режим. Лучше всего использовать Kit – набор из двух и более модулей памяти, которые уже были проверены при работе с друг другом. Эти модули памяти одного производителя, с одинаковым объемом и одинаковой частотой.

При использовании двух идентичных модуля памяти DDR3 в двухканальном режиме позволяет повысить пропускную способность до 17.0 Гбайт/с. Если использовать оперативную память с 1333 Мгц, то пропускная способность повысится до 21.2 Гбайт/с.
Современные внутренние шины – смена приоритетов!
Среди наиболее динамично развивающихся областей компьютерной техники стоит отметить сферу технологий передачи данных: в отличие от сферы вычислений, где наблюдается продолжительное и устойчивое развитие параллельных архитектур, в «шинной» 1 сфере, как среди внутренних, так и среди периферийных шин, наблюдается тенденция перехода от синхронных параллельных шин к высокочастотным последовательным. (Заметьте, «последовательные» – не обязательно значит «однобитные», здесь возможны и 2, и 8, и 32 бит ширины при сохранении присущей последовательным шинам пакетной передачи данных, то есть в пакете импульсов данные, адрес, CRC и другая служебная информация разделены на логическом уровне 2 ).
1 Компьютерная шина (магистраль передачи данных между отдельными функциональными блоками компьютера) – совокупность сигнальных линий, объединённых по их назначению (данные, адреса, управление), которые имеют определённые электрические характеристики и протоколы передачи информации. Шины отличаются разрядностью, способом передачи сигнала (последовательные или параллельные), пропускной способностью, количеством и типами поддерживаемых устройств, протоколом работы, назначением (внутренняя, интерфейсная).
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также могут использовать мультиплексирование (передачу адреса и данных по одним и тем же линиям) и различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами).
2 Основным отличием параллельных шин от последовательных является сам способ передачи данных. В параллельных шинах понятие «ширина шины» соответствует её разрядности – количеству сигнальных линий, или, другими словами, количеству одновременно передаваемых («выставляемых на шину») битов информации. Сигналом для старта и завершения цикла приёма/передачи данных служит внешний синхросигнал. В последовательных же каналах передачи используется одна сигнальная линия (возможно использование двух отдельных каналов для разделения потоков приёма-передачи). Соответственно, информационные биты здесь передаются последовательно. Данные для передачи через последовательную шину облекаются в пакеты (пакет – единица информации, передаваемая как целое между двумя устройствами), в которые, помимо собственно полезных данных, включается некоторое количество служебной информации: старт-биты, заголовки пакетов, синхросигналы, биты чётности или контрольные суммы, стоп-биты и т. п. Но в свете последних достижений в «железной» сфере компьютерной индустрии малое количество сигнальных линий и логически более сложный механизм передачи данных последовательных шин оборачиваются для них существенным преимуществом – возможностью практически безболезненного наращивания рабочих частот в таких пределах, каких никогда не достичь громоздким параллельным шинам с их высокочастотными проблемами ожидания доставки каждого бита к месту назначения. Проблема в том, что каждая линия такой шины имеет свою длину, свою паразитную ёмкость и индуктивность и, соответственно, своё время прохождения сигнала от источника к приёмнику, который вынужден выжидать дополнительное время для гарантии получения данных по всем линиям. Так, к примеру, каждый байт, передаваемый через линк шины PCIExpress, для увеличения помехозащищённости «раздувается» до 10 бит, что, однако, не мешает шине передавать до 0,25 ГБ за секунду по одной паре проводов. Да, ширина последовательной шины на самом деле является количеством одновременно задействованных отдельных последовательных каналов передачи.
Все эти нововведения и смена приоритетов преследуют в конечном итоге одну цель – повышение суммарного быстродействия системы, ибо не все существующие архитектурные решения способны эффективно масштабироваться. Несоответствие пропускной способности шин потребностям обслуживаемых ими устройств приводит к эффекту «бутылочного горлышка» и препятствует росту быстродействия даже при дальнейшем увеличении производительности вычислительных компонентов – процессора, оперативной памяти, видеосистемы и так далее.
Процессорная шина
Любой процессор архитектуры x86CPU обязательно оснащён процессорной шиной. Эта шина служит каналом связи между процессором и всеми остальными устройствами в компьютере: памятью, видеокартой, жёстким диском и так далее. Так, классическая схема организации внешнего интерфейса процессора (используемая, к примеру, компанией Intel в своих процессорах архитектуры х86) предполагает, что параллельная мультиплексированная процессорная шина, которую принято называть FSB (Front Side Bus), соединяет процессор (иногда два процессора или даже больше) и контроллер, обеспечивающий доступ к оперативной памяти и внешним устройствам. Этот контроллер обычно называют северным мостом , он входит в состав набора системной логики ( чипсета ).
Используемая Intel в настоящее время эволюция FSB – QPB , или Quad-Pumped Bus, способна передавать четыре блока данных за такт и два адреса за такт! То есть за каждый такт синхронизации шины по ней может быть передана команда либо четыре порции данных (напомним, что шина FSB–QPB имеет ширину 64 бит, то есть за такт может быть передано до 4х64=256 бит, или 32 байт данных). Итого, скажем, для частоты FSB, равной 200 МГц, эффективная частота передачи адреса для выборки данных будет эквивалентна 400 МГц (2х200 МГц), а самих данных – 800 МГц (4х200 МГц) 3 .
3 Кстати, именно результирующей «учетверённой» частотой передачи данных (как и в случае с «удвоенной» передачей DDR-шины, где данные передаются дважды за такт) хвастаются производители и продавцы, умалчивая тот факт, что для многочисленных мелких запросов, где данные в большинстве своём умещаются в одну 64-байтную порцию (и, соответственно, не используются возможности DDR или QDR/QPB), на чтение/запись важнее именно частота тактирования.
В архитектуре же AMD64 (и её микроархитектуре K8), используемой компанией AMD в своих процессорах линеек Athlon 64/Sempron/Opteron, применён революционно новый подход к организации интерфейса центрального процессора – здесь имеет место наличие в самом процессоре нескольких отдельных шин. Одна (или две – в случае двухканального контроллера памяти) шина служит для непосредственной связи процессора с памятью, а вместо процессорной шины FSB и для сообщения с другими процессорами используются высокоскоростные шины HyperTransport. Преимуществом данной схемы является уменьшение задержек (латентности) при обращении процессора к оперативной памяти, ведь из пути следования данных по маршруту «процессор – ОЗУ» (и обратно) исключаются такие весьма загруженные элементы, как интерфейсная шина и контроллер северного моста.
Различия реализации классической архитектуры и АМD-K8
Различия реализации классической архитектуры и АМD-K8
Ещё одним довольно заметным отличием архитектуры К8 является отказ от асинхронности, то есть обеспечение синхронной работы процессорного ядра, ОЗУ и шины HyperTransport, частоты которых привязаны к «шине» тактового генератора (НТТ), которая в этом случае является опорной. Таким образом, для процессора архитектуры К8 частоты ядра и шины HyperTransport задаются множителями по отношению к НТТ, а частота шины памяти выставляется делителем от частоты ядра процессора 4
4 Пример: для системы на базе процессора Athlon 64-3000+ (1,8 ГГц) с установленной памятью DDR-333 стандартная частота ядра (1,8 ГГц) достигается умножением на 9 частоты НТТ, равной 200 МГц, стандартная частота шины HyperTransport (1 ГГц) – умножением НТТ на 5, а частота шины памяти (166 МГц) – делением частоты ядра на 11.
В классической же схеме с шиной FSB и контроллером памяти, вынесенным в северный мост, возможна (и используется) асинхронность шин FSB и ОЗУ, а опорной частотой для процессора выступает частота тактирования 5 (а не передачи данных) шины FSB, частота же тактирования шины памяти может задаваться отдельно. Из наиболее свежих чипсетов возможностью раздельного задания частот FSB и памяти обладает NVIDIA nForce 680i SLI, что делает его отличным выбором для тонкой настройки системы (разгона).